
データマイニングを用いた労働災害分析
1.はじめに
労働災害防止対策を検討する際に、労働災害事例の分析は欠かせません。厚生労働省が公表している労働災害(死傷)データベース(1)(以下労災DBという)はこのような分析に重要なデータ源となっています。労災DBでは、1件の災害事例は一つのレコードに対応し、業種、事業所規模、被災者年齢、性別、経験期間、休業日数及び災害発生状況などの属性で構成されています(図1)。本コラムでは、この労災DBを用いた災害分析について、従来から行われている集計及びクロス分析の問題点とデータマイニング手法の適用について説明します。
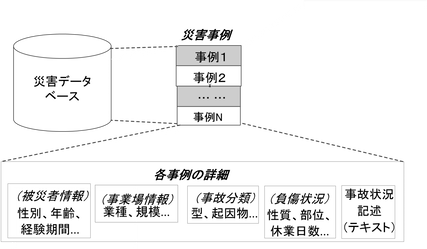
図1 労働災害(死傷)データベースの構成
2.労災DBを用いた集計分析とクロス分析
労災DBを用いてよく行う分析として、属性ごとの集計分析があります。例えば、平成18年労災DBには、死亡災害を除いた休日4日以上の全事例の1/4サンプルとして、33,942件の事例が収録されています。これらの事例分析で事故の型に注目したい時には、図2に示すような事故の型の集計が行われます。この集計により、転倒による事故が一番多いことが分かります。
また、転倒は主にどのような起因物と関係があるかを知りたい場合、転倒型災害事例の中から、起因物について集計を行うことで分かります。このとき、Excelを用いた分析作業として、図3に示すように事故の型と起因物の間のクロス分析(=二つの属性間関係の分析)を行います。図3によると、転倒型事例の中で、一番多い起因物は「G04仮設物・建築物・構造物等」の分類となっています。一方、起因物以外の他の要因と関係する転倒災害は無いでしょうか? 例えば、高齢労働者の事故は多いと言われていますが、転倒は年齢と、どんな関係があるのでしょうか? このような疑問を解くには、「事故の型=転倒」の事例について年齢に対する集計を行う必要がありますが、上記「事故の型×起因物」と同様に、「事故の型×年齢」のクロス分析を行うことになります。
一方、図1にも示しているように、災害事例の属性は事故の型、起因物、年齢の他に、業種、事業所規模、性別、経験期間、休業日数なども多数あります。様々な角度から災害分析を行うには、様々なペアの属性に対してクロス分析を行う必要がありますが、すべての属性ペア毎にクロス分析を実施すると、かなり手間がかかります。
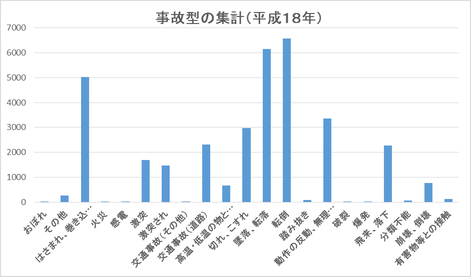
図2 集計分析の例
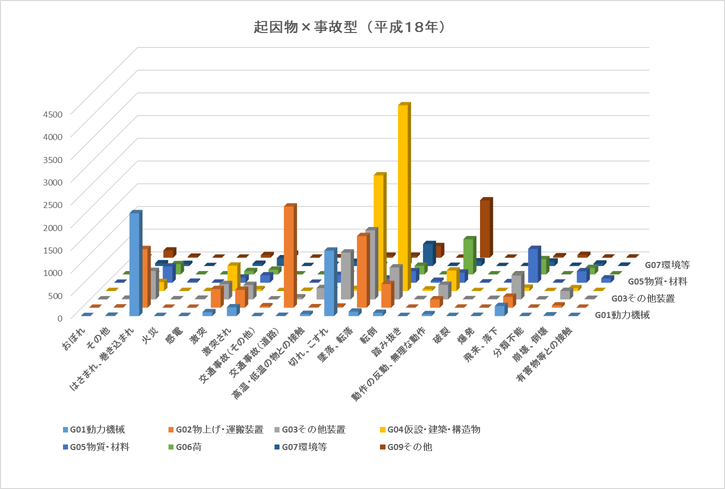
図3 クロス分析の例
3.アソシエーション分析
効率良くクロス分析を行うために、知識と経験に基づく属性ペアの選択が行われますが、新しい知識を見逃す可能性もあります。そこで、災害データ分析の新たな手法としてデータマイニングの導入を検討しています。
データマイニングとは膨大な量のデータの中に隠された有意な知識を発掘するデータ分析手法です(2,3)。データマイニング手法に対する詳しい説明は本コラムの範囲を超えるので省略しますが、ここではデータマイニング手法の一つ、アソシエーション分析の基本概念を述べた後、労災DBに適用した分析結果を紹介します。
アソシエーション分析は、アソシエーションルールと呼ばれる二つの事象間のつながりの強さに関する規則を、知識として発見する方法です。図4に示すように、二つの事象AとBの間の関連性の強さは、AとBの重なり部分がAとBに占める割合により説明できます。アソシエーション分析はある事象Aが発生した時に、別の事象Bが発生するルール(A→Bとして表記)を求めます。ここで、AとBをそれぞれルールの「前提」と「結論」と言います。
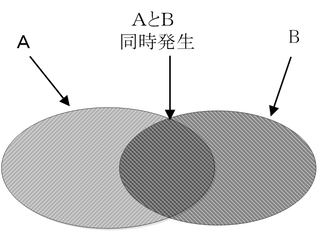
図4 二つの事象の関連性
アソシエーション分析の課題は、二つの事象の組み合わせ全てをルールとして抽出すると、大きなデータに対しては必然的に膨大な量の組み合わせを見つけてしまうことになります。その結果、有意なルールが単なるノイズに埋もれてしまう場合もあります。そこで、ルールの有意性を測る指標サポート(Support) と信頼度(Confidence)が必要になります。
【サポート(Support)】ルールA→BのサポートはAとBが同時に発生する事象が全事象に占める割合。
【信頼度(Confidence)】ルールA→Bの信頼度はAとBが同時に発生する事象が事象Bに占める割合。つまり、ルールA→Bの信頼度は事象Aが発生した場合に事象Bが発生する確率。
信頼度とサポートの値に閾値を設けることにより、重要なルールのみを抽出することができます。
4.労災DBにアソシエーション分析を適用した結果
データマイニングツールVisual Mining Studio(4)のアソシエーション分析機能を用いて、平成18年労災DB(死亡事例を除く)33,942件の事例を分析しました。分析の対象属性は業種、事業所規模、年齢層、経験期間、事故の型、起因物、負傷部位、休業日数の8つです。「信頼度>50%、サポート>5%」に設定した分析結果を表1に示します。
表1の一行は一つのルールに対応します。例えば、表1の4行目は下記ルールを表します:
【起因物=動力機械】→【傷病部位=上肢】
表1より、「信頼度」は73.0%となり、動力機械を起因物とする災害の中で、73%の被災者の傷病部位が上肢であることを意味します。また、「サポート」の値9.7%は「起因物=動力機械」かつ「傷病部位=上肢」の災害事例数(表1に「事例数」の列で表す)3,286が全災害事例33,942件に占める割合です。このことは、動力機械のリスク低減策として、上肢保護策を検討することが重要であることを示唆します。
次に、表1の6行目の下記ルールに注目します。
【事故の型=転倒】→【起因物=G04仮設物・建築物・構造物等】
このルールの信頼度62.3%、転倒による事故の中で、起因物は「G04仮設物・建築物・構造物等」となるものが62.3%あることを示します。これは2章で述べた集計分析とクロス分析による結果と一致します。また、表1の中に転倒による事故と年齢の関係を示したルールはありません。これは転倒による事故の、年齢との関連性が低いことを意味します。
表1 アソシエーション分析結果
(信頼度>50%、サポート>5%のルールのみを抽出

5.おわりに
データマイニング手法のアソシエーション分析を平成18年労災DBに適用した例について説明しました。従来EXCELを用いたクロス分析手法では、一回の分析作業では二つの属性の関係しか得ることができませんが、データマイニングツールのアソシエーション分析を用いれば、表1に示すように多数の属性間の関係を一括で得ることができます。これはデータマイニング手法のメリットと言えます。また、信頼度及びサポートに対する閾値の調整、及び災害事例の属性条件を設定することで、労働災害に関する様々な知識(ルール)を発見することも可能です。
参考文献
- 厚生労働省, 労働災害(死傷)データベース, http://anzeninfo.mhlw.go.jp
- Kashani T, Mohaymany AS, Rajbari A., “A data mining approach to identify key factors of traffic injury severity”, Promet-traffic & Transportation, vol. 23, (2011)
- 呂健, “労働災害事例分析へのデータマイニング適用の試み”, 安全工学シンポジウム予稿集, pp.380-381(2018)
- (株)NTTデータ数理システム, Visual Mining Studio 8.2技術資料
 |
 |
 |
 |
 |